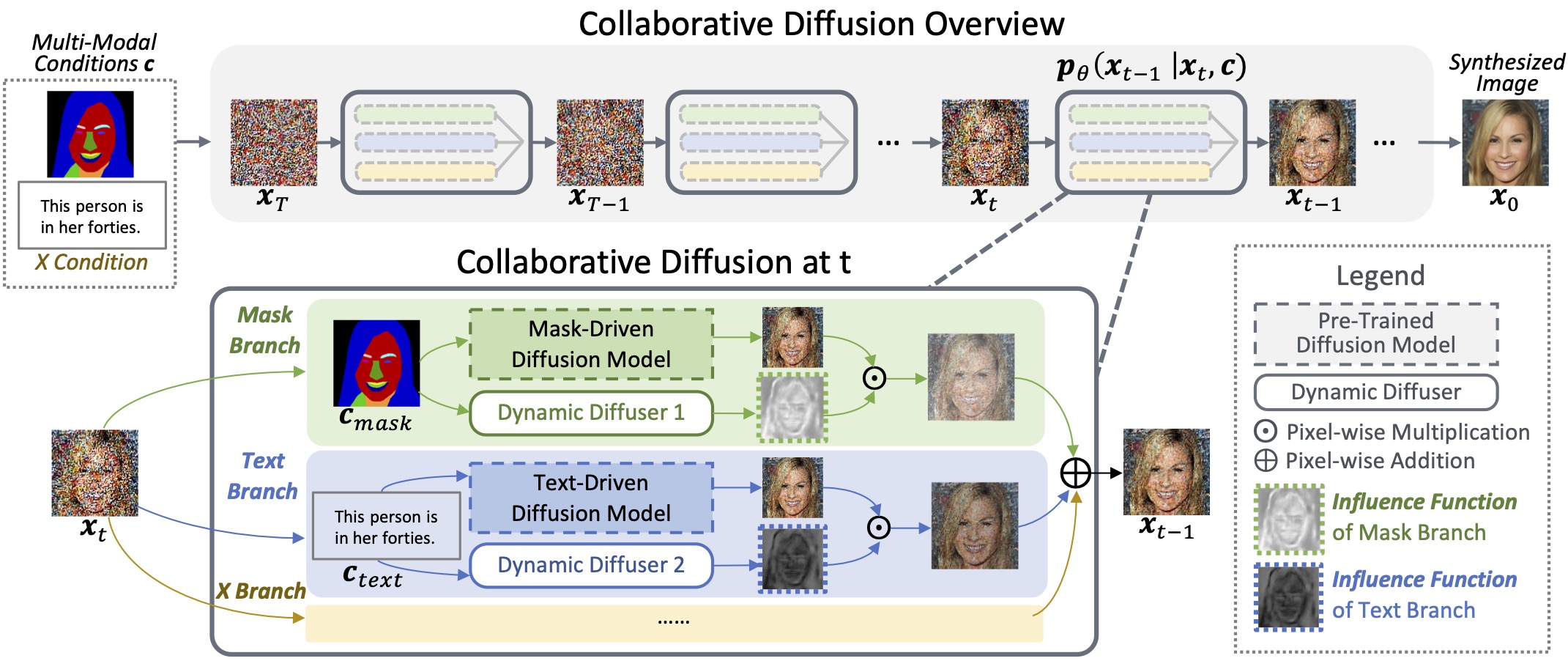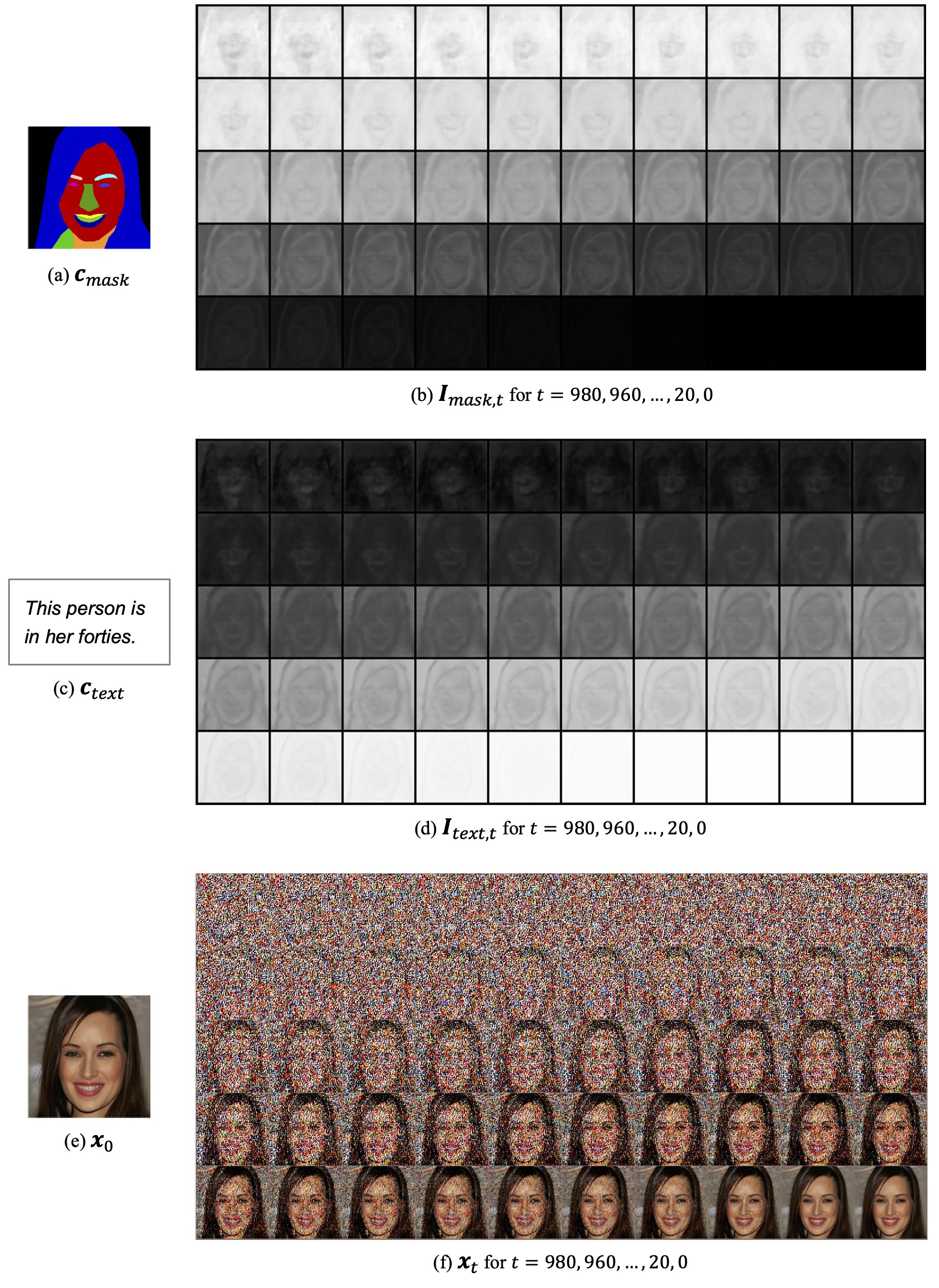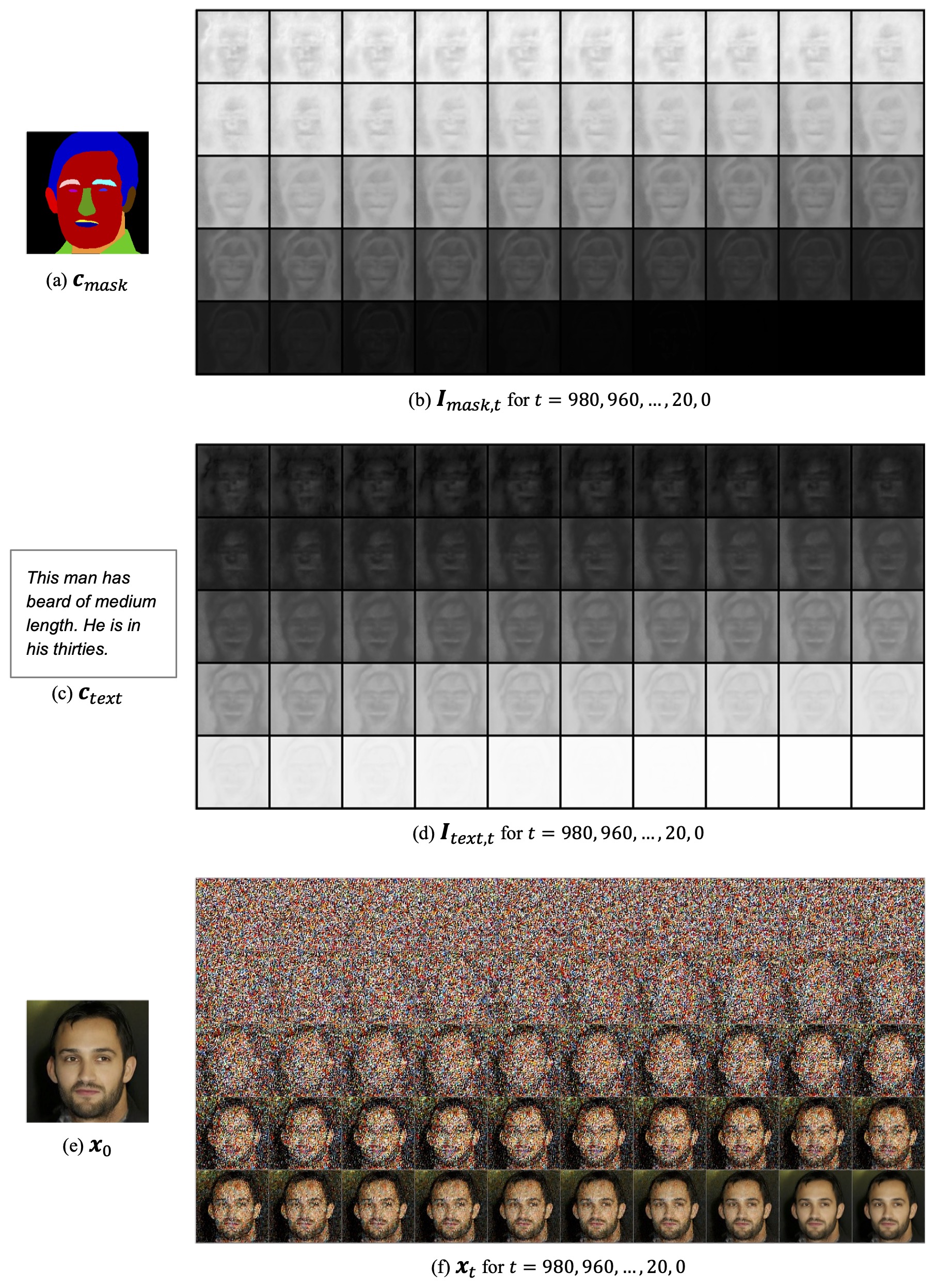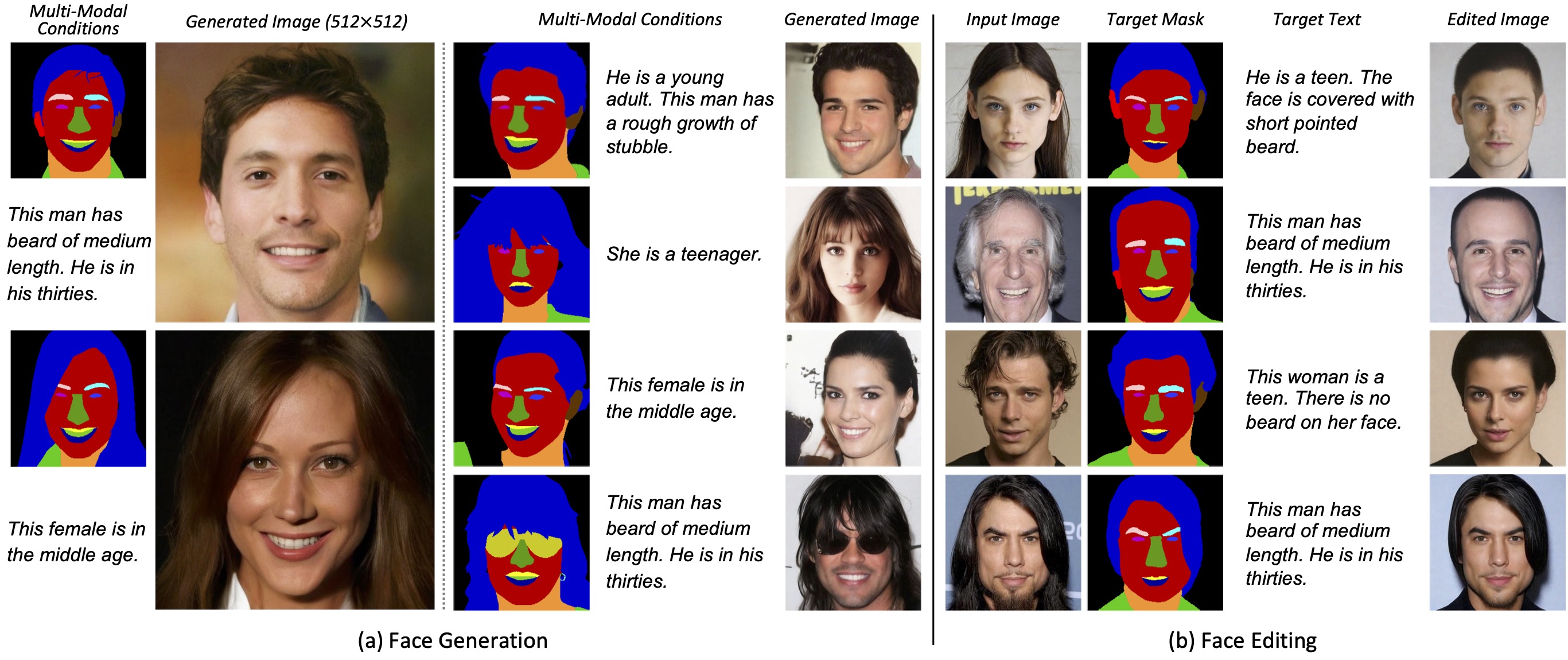
We propose Collaborative Diffusion, where users can use multiple modalities to control face generation and editing.
(a) Face Generation. Given multi-modal controls, our framework synthesizes high-quality images consistent with the input conditions. (b) Face Editing. Collaborative Diffusion also supports multi-modal editing of real images with promising identity preservation capability.